
Gemini 3.1 Pro: Benchmarks, Real Gains, and Where It Actually Matters
A practical breakdown of Gemini 3.1 Pro (Feb 2026): key benchmark changes, agentic workflow impact, and when teams should (or should not) switch.
Google just released Gemini 3.1 Pro, and this is one of those launches worth evaluating with a clear head: no hype, no cynicism, just practical impact.
In this guide, we’ll cover:
- what changed versus Gemini 3 Pro,
- which benchmark deltas are meaningful,
- where 3.1 Pro can reduce real delivery time,
- and where teams should stay skeptical.
TL;DR
- Gemini 3.1 Pro (preview) is a serious reasoning + agentic workflow upgrade.
- The biggest public jump appears on ARC-AGI-2: 77.1% vs 31.1%.
- Gains also show up on APEX-Agents, BrowseComp, and Terminal-Bench 2.0.
- The strongest business upside is in tasks combining long context, coding, tools, and multi-step execution.
- It is not an “autopilot model.” Process quality still matters more than benchmark headlines.
What Google Announced
In the official launch update (Feb 19, 2026), Google positioned Gemini 3.1 Pro for harder, reasoning-heavy workloads and rolled it out across:
- Gemini API / AI Studio,
- Vertex AI and Gemini Enterprise,
- Gemini app and NotebookLM (higher-tier plans).
That positioning aligns with the benchmark profile: less about simple chat, more about complex execution quality.
Benchmarks That Matter in Practice
Here is a compact comparison between Gemini 3 Pro and Gemini 3.1 Pro on selected public metrics.
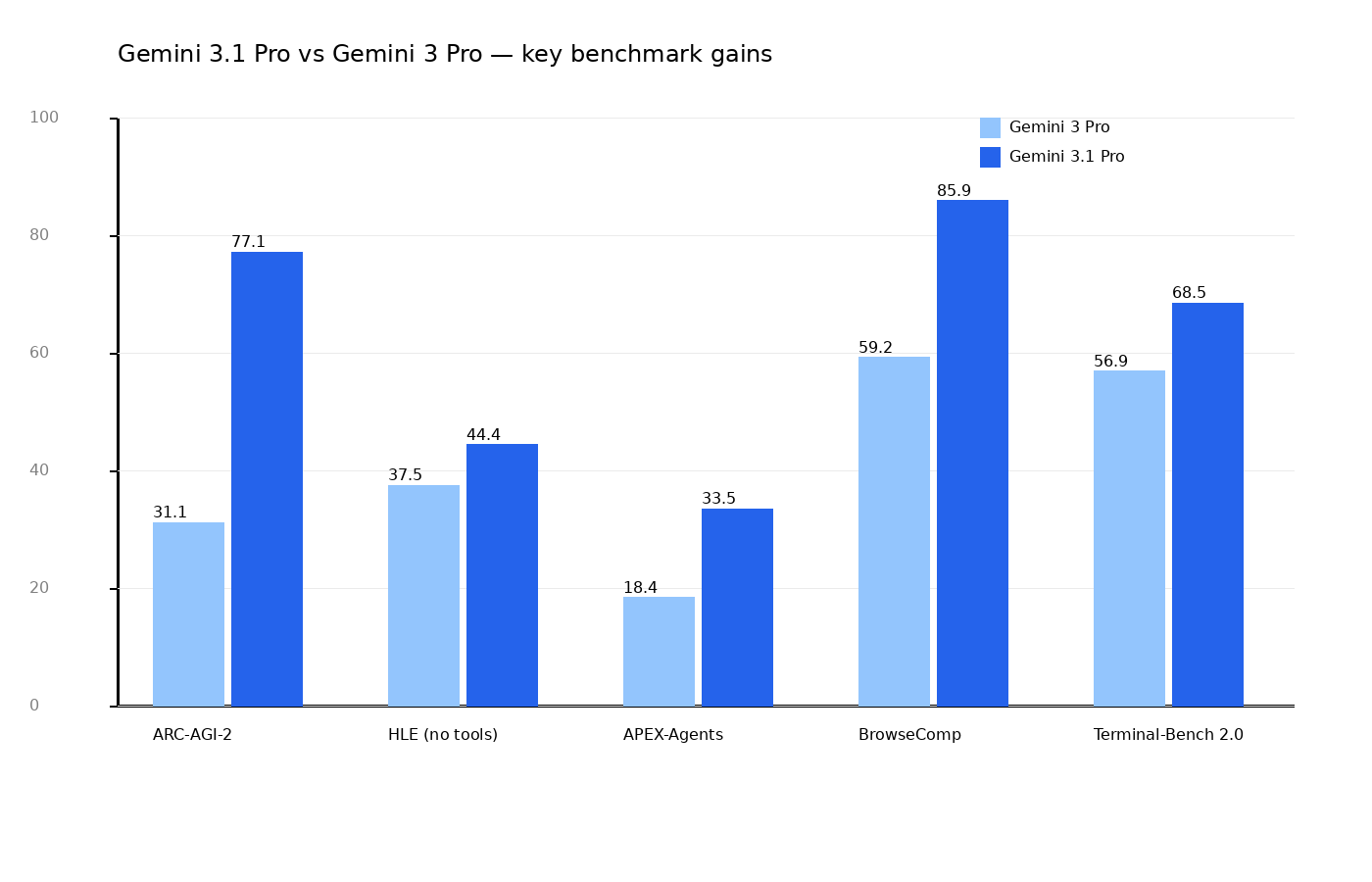
ARC-AGI-2: the standout jump
- Gemini 3.1 Pro: 77.1%
- Gemini 3 Pro: 31.1%
ARC-AGI-2 is useful because it tests novel pattern reasoning, not simple memorization.
Humanity’s Last Exam (no tools)
- Gemini 3.1 Pro: 44.4%
- Gemini 3 Pro: 37.5%
Not as dramatic as ARC, but still a meaningful improvement.
Agentic benchmarks
- APEX-Agents: 33.5% vs 18.4%
- BrowseComp: 85.9% vs 59.2%
- Terminal-Bench 2.0: 68.5% vs 56.9%
For operational teams, these deltas can matter more than generic “IQ-like” benchmark rankings.
Quick Competitor Snapshot
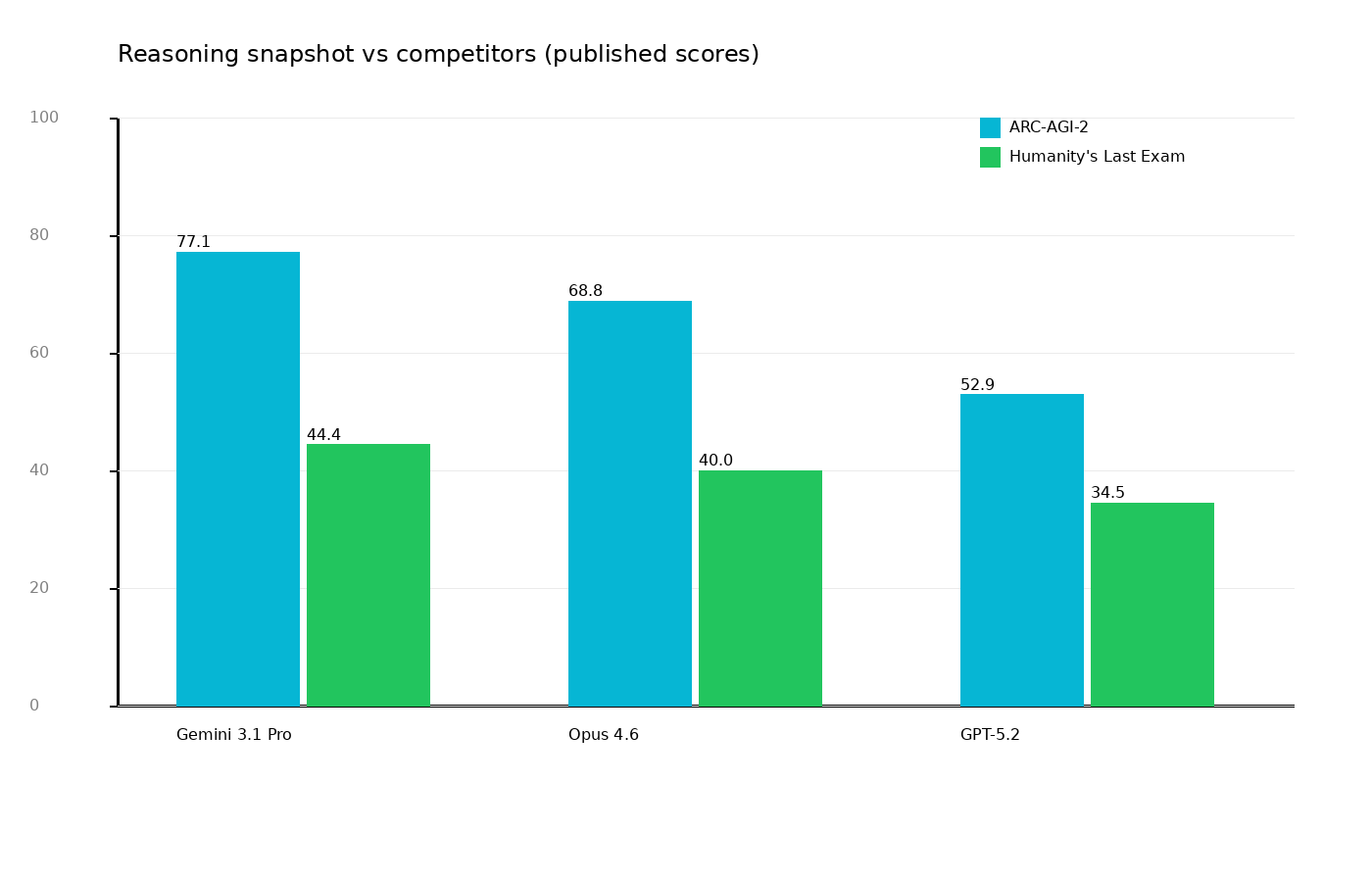
On two high-visibility reasoning tests (ARC-AGI-2 and Humanity’s Last Exam), Gemini 3.1 Pro looks very strong. Still, be cautious:
- benchmark setups vary,
- different harnesses can favor different model behaviors,
- production outcomes depend more on workflow than any single leaderboard cell.
Where 3.1 Pro Can Deliver Real ROI
1) Complex analysis-to-execution tasks
If your process includes analysis, synthesis, code generation, and iterative refinement, stronger reasoning typically means fewer costly detours.
2) Agentic pipelines
If you run planner → builder → reviewer style systems, better agentic benchmark performance can translate into:
- shorter lead time,
- fewer manual corrections,
- more stable multi-step outputs.
3) Coding with long context
When the model must hold repo structure, constraints, business logic, and non-functional requirements together, stronger context handling often improves consistency.
Where Teams Should Stay Realistic
Better benchmark ≠ hands-free delivery
No model upgrade replaces:
- test discipline,
- quality gates,
- explicit task contracts,
- production accountability.
Process beats leaderboard
Your outcomes still depend on:
- scope control,
- review rigor,
- definition of done,
- rollback/monitoring strategy.
Model capability is a multiplier, not a substitute for engineering hygiene.
A Minimal, Low-Risk Rollout Playbook
- Pick 2–3 pilot workflows (e.g., content research, SEO automation, coding assistant tasks).
- Define baseline KPIs (time, quality, correction rate).
- Run a 2-week A/B: previous model vs Gemini 3.1 Pro.
- Keep the workflow constant (same checklists, same acceptance criteria).
- Compare business outcomes, not just answer style.
Final Take
Gemini 3.1 Pro is more than a cosmetic increment. Public benchmark movement is especially notable in reasoning and agentic task profiles.
Is it the best choice for every workload? No.
Is it worth immediate testing in high-complexity, long-context pipelines? Absolutely.
Sources
- Google Blog: Gemini 3.1 Pro launch (Feb 19, 2026)
- Google DeepMind: Gemini 3.1 Pro Model Card (published benchmark table)
- Ars Technica: independent context and comparison notes