
Gemini 3.1 Pro: benchmarki, realne zyski i kiedy warto go wdrażać
Premiera Gemini 3.1 Pro (19.02.2026): co faktycznie poprawiono, jak wyglądają benchmarki (ARC-AGI-2, HLE, APEX-Agents, BrowseComp) i gdzie ten model daje przewagę biznesową.
Google właśnie wypuścił Gemini 3.1 Pro i to jest jedna z tych premier, które naprawdę warto ocenić chłodno: bez hajpu, ale też bez marudzenia „kolejny model, who cares”.
W tym tekście robimy szybki i praktyczny breakdown:
- co nowego względem Gemini 3 Pro,
- które benchmarki faktycznie mają znaczenie,
- gdzie 3.1 Pro może skrócić realny czas dowożenia,
- i gdzie nadal lepiej zachować sceptycyzm.
TL;DR
- Gemini 3.1 Pro (preview) to upgrade w stronę bardziej złożonego reasoning + pracy agentowej.
- Największy skok z publicznych liczb widać na ARC-AGI-2: 77.1% vs 31.1% w Gemini 3 Pro.
- W benchmarkach typu APEX-Agents, BrowseComp, Terminal-Bench 2.0 też widać poprawę.
- W praktyce największa przewaga to zadania, gdzie trzeba połączyć: długi kontekst, kod, iteracje i narzędzia.
- To nie jest „magiczny autopilot”. Nadal kluczowe są bramki jakości i kontrola workflow.
Co dokładnie ogłoszono
Według oficjalnej publikacji Google (19.02.2026), Gemini 3.1 Pro jest wdrażany równolegle do:
- Gemini API / AI Studio,
- Vertex AI i Gemini Enterprise,
- Gemini app i NotebookLM (dla wyższych planów).
Pozycjonowanie jest jasne: model pod „trudniejsze przypadki”, czyli nie tylko Q&A, ale złożone łączenie danych, coding i taski agentowe.
Benchmarki, które warto obserwować
Poniżej szybki wykres porównujący 3 Pro vs 3.1 Pro w kilku publicznie cytowanych testach.
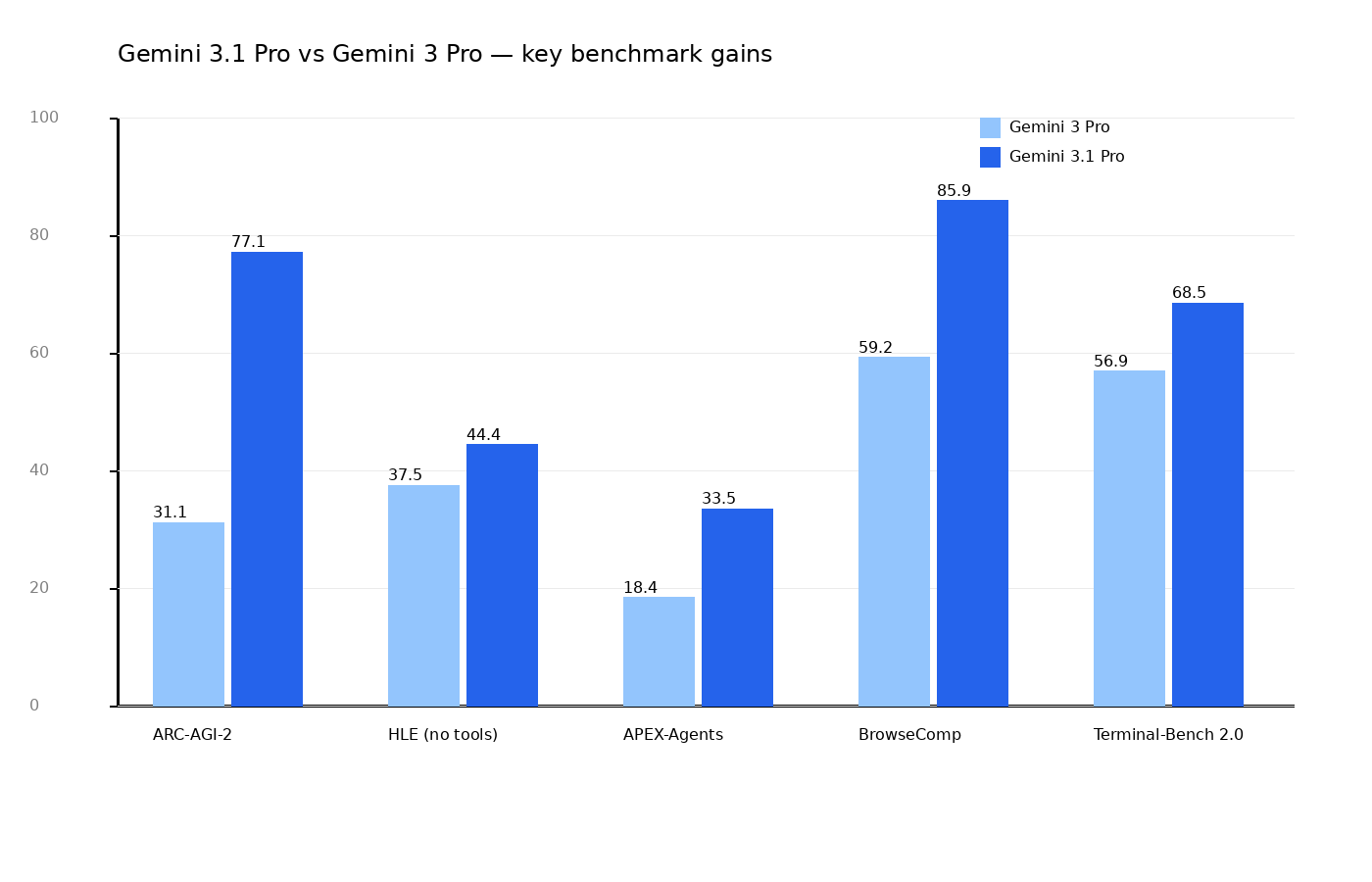
Najbardziej widoczny skok: ARC-AGI-2
- Gemini 3.1 Pro: 77.1%
- Gemini 3 Pro: 31.1%
To test abstrakcyjnego reasoningu na nowych wzorcach. Nie mierzy „czy model zna odpowiedź z internetu”, tylko czy potrafi dojść do reguły.
Humanity’s Last Exam (bez narzędzi)
- Gemini 3.1 Pro: 44.4%
- Gemini 3 Pro: 37.5%
Różnica mniejsza niż na ARC, ale nadal wyraźna.
Agentowe benchmarki operacyjne
- APEX-Agents: 33.5% vs 18.4%
- BrowseComp: 85.9% vs 59.2%
- Terminal-Bench 2.0: 68.5% vs 56.9%
To ważniejsze dla firm niż „suche IQ modelu”, bo dotyka realnych scenariuszy: wyszukiwanie, narzędzia, kod i dłuższe sekwencje działań.
Snapshot vs konkurencja (publikowane liczby)
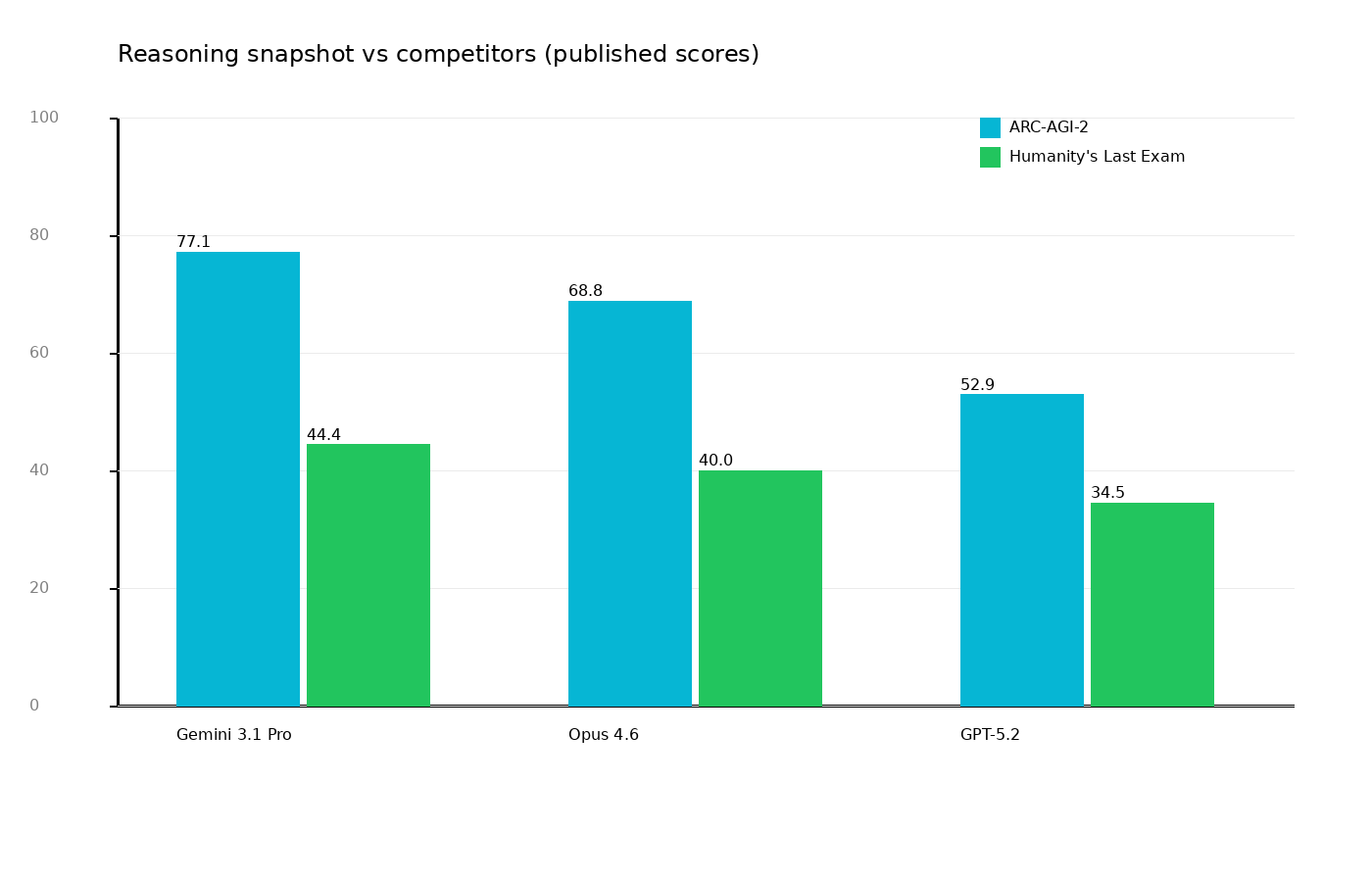
Dla dwóch głośnych testów (ARC-AGI-2 i HLE) 3.1 Pro wypada bardzo mocno. Jednocześnie trzeba pamiętać, że:
- benchmarki mają różne harnessy i setupy,
- część testów premiuje konkretne style odpowiedzi,
- wyniki w produkcji zależą bardziej od workflow niż od samej tabelki.
Gdzie 3.1 Pro może dać największy zwrot
1) Złożone taski „analysis + execution”
Przykład: analiza danych + wygenerowanie rekomendacji + szybki prototyp + iteracja z feedbackiem.
Tu model z lepszym reasoningiem i dłuższym kontekstem zwykle daje mniej „gubienia wątku” i mniej kosztownych nawrotek.
2) Workflow agentowe
Jeśli działasz na wzorcu planner → builder → reviewer, poprawa na benchmarkach agentowych może przełożyć się na realne KPI:
- krótszy lead time,
- mniej ręcznych poprawek,
- lepsza stabilność odpowiedzi przy wieloetapowych taskach.
3) Coding z większą ilością kontekstu
Gdy agent musi „trzymać w głowie” repo + wymagania + ograniczenia SEO/perf, mocniejszy model zwykle daje:
- mniej błędnych założeń,
- lepszą spójność zmian,
- mniej losowych regresji.
Gdzie nie warto przesadzać z oczekiwaniami
„Lepiej w benchmarku” ≠ „bezobsługowe wdrożenie”
Nawet bardzo dobry model nie zastąpi:
- testów i walidacji,
- dobrego prompt contractu,
- bramek QA,
- odpowiedzialności po stronie zespołu.
Produkt wygrywa procesem, nie leaderboardem
W praktyce to proces decyduje o wyniku:
- jak dzielicie zadania,
- jak wygląda review,
- jak mierzycie „done”,
- czy macie rollback i monitoring.
Model jest mnożnikiem, nie substytutem systemu pracy.
Minimalny playbook wdrożenia Gemini 3.1 Pro (bez chaosu)
- Wybierz 2–3 procesy pilotażowe (np. research contentowy, automatyzacja SEO, coding helper).
- Ustal baseline KPI (czas, jakość, liczba poprawek).
- Uruchom A/B przez 2 tygodnie: stary model vs 3.1 Pro.
- Wymuś ten sam workflow (te same checklisty i kryteria jakości).
- Porównaj wynik biznesowy, nie tylko „jak mądrze brzmi odpowiedź”.
Co to oznacza dla właścicieli firm i zespołów
Jeżeli budujesz procesy oparte o AI, premiera 3.1 Pro jest dobrą okazją do przeglądu stacku — ale nie jako „zmiana dla zmiany”.
Najrozsądniejsze podejście:
- podmienić model tylko tam, gdzie masz mierzalny use-case,
- utrzymać rygor jakości,
- dokumentować decyzje i wyniki,
- skalować dopiero po potwierdzonym zwrocie.
To jest dokładnie różnica między „testowaniem nowinek” a budowaniem przewagi operacyjnej.
Podsumowanie
Gemini 3.1 Pro to nie kosmetyczny patch. W wybranych benchmarkach skok jest wyraźny, szczególnie tam, gdzie liczy się reasoning i agentowe dowożenie zadań.
Czy to model dla każdego use-case’u? Nie.
Czy warto go sprawdzić tam, gdzie pracujesz na złożonych procesach i dużym kontekście? Zdecydowanie tak.
Źródła
- Google Blog: Gemini 3.1 Pro announcement (19.02.2026)
- Google DeepMind: Gemini 3.1 Pro Model Card (publikowane wyniki benchmarków)
- Ars Technica: analiza i kontekst porównawczy